J’ai entrepris de traduire deux articles écrits et publiés le 12 avril dernier parSebastian Posth, à propos du Content Blockchain Project. Un grand merci à Sebastian pour m’avoir autorisée à publier ces traductions, et merci aussi pour sa relecture fort utile.
Qu’est-ce qu’une « Smart License » ?
par Sebastian Posth (voir l’ article original en anglais)
Le Content Blockchain Project construit les outils de base qui vont permettre aux journalistes, éditeurs et aux start-ups du secteur des médias de créer des produits, des services et des modèles d’affaires innovants dans l’économie ouverte de la blockchain.
–> Si vous avez lu le précédent article, passez l’introduction, qui est commune aux deux articles.
L’idée fondamentale derrière le Content Blockchain Project a été de créer les fondations techniques d’un environnement d’échange pour des contenus média numériques qui faciliterait de nouvelles manières de proposer et d’acheter du contenu sur un réseau décentralisé de la blockchain.
Son but est de simplifier le processus complexe de management des licences et de distribution des contenus numériques en offrant un registre de droits et de licences sous la forme d’un «grand registre ouvert et transparent» géré par la blockchain.
Pour les ayants droit et pour les intermédiaires il devrait être facile et peu coûteux de publier les termes des licences d’utilisation de leurs contenus.
Pour les utilisateurs, qu’il s’agisse d’entreprises ou de particuliers, il devrait être simple et peu coûteux d’avoir accès aux termes de ces licences et d’acheter les contenus sous licence selon les termes proposés.
Cela s’applique à toute application ou à tout service dont l’objectif est d’offrir et de licencier du contenu via la blockchain de manière semi-automatisée: identification de contenu et gestion des licences sont les prérequis indispensables.
Les principaux défis pour le Content Blockchain Project ont été:
-
de trouver le moyen d’identifier sans ambiguïté des contenus numériques
-
d’offrir une solution intelligente pour le management des droits et l’information sur les licences, en rendant les termes des licences lisibles par des machines et en permettant l’attribution automatique de licences.
Dans un premier article, j’ai décrit l’approche concernant l’identification poursuivie par le Content Blockchain Project ces derniers mois.
Dans ce second article, j’aimerais décrire l’approche concernant la gestion de licence que le Content Blockchain Project a poursuivie durant les derniers mois. Ces deux articles sont destinés aux parties prenantes de l’industrie des médias, avec une introduction, qui évite le jargon technique ou juridique, à deux éléments que nous avons développés dans le projet: l’identifiant de contenu ISCC et les Smart Licenses pour les médias numériques.
Merci de considérer cette approche comme un proposition. Nous apprécierons beaucoup vos retours et réactions.
Créer une Smart License
Tout comme l’ ISCC lie sans aucune équivoque et de manière inséparable un contenu spécifique à un identifiant spécifique, la Smart License lie sans aucune équivoque et de manière inséparable les termes d’une licence spécifique à un contenu spécifique. Cela signifie que n’importe qui, en capacité d’accéder à ce contenu, aura également accès au terme de la licence qui lui est associée, s’il est enregistré dans la Content Blockchain. C’est une révolution dans la publication de médias digitaux.
Le terme «Smart License» ne doit pas être confondu avec celui de «Smart Contract». Une Smart License n’est pas un ‘ protocole technique destiné à faciliter numériquement, vérifier ou faire respecter la négociation ou l’exécution d’un contrat‘.
Les Smart Licenses sont des représentations légales qui permettront aux détenteurs de droits d’offrir et d’échanger du contenu de manière globale, de manière sécurisée et fiable, ouverte et transparente, automatisée et lisible par des machines sur la Content Blockchain.
En conséquence, les Smart Licenses offriront aux intermédiaires, aux détaillants et aux utilisateurs un accès facile aux licences de contenu et un moyen de les vérifier et de les acheter de manière simple et potentiellement automatisée.
Les Smart Licenses sont formulées de manière à être faciles à comprendre et à utiliser par tous.
Ressources :
Générateur de Smart Licenses:
http://smartlicense.coblo.net/
Générateur de Smart Licenses — Code disponible sur GitHub
https://github.com/coblo/smartlicense
Ce document spécifie les structures de données, les flux de données, et les modèles de transaction qui sont utilisés pour publier et vérifier les licences lisibles par des machines ainsi que les règles d’établissement de contrats sur la Content Blockchain.
https://content-blockchain.org/drafts-and-concepts/smart-license-v1-0/
Avis légal Smart License (v. 0.9.9)
https://content-blockchain.org/drafts-and-concepts/content-blockchain-b2c-smart-license/
modules de définition des Smart License (v. 0.9.2)
https://content-blockchain.org/drafts-and-concepts/smart-license-definition-license-modules/
The Content Blockchain Project a développé un prototype pour un générateur de Smart Licenses. Cette application va autoriser les détenteurs de droits à générer des licences pour du contenu numérique très facilement, en quelques clics.
Une application de démonstration sur le réseau test Blockchain peut être trouvée en ligne:
http://smartlicense.coblo.net/
 http://smartlicense.coblo.net/
http://smartlicense.coblo.net/
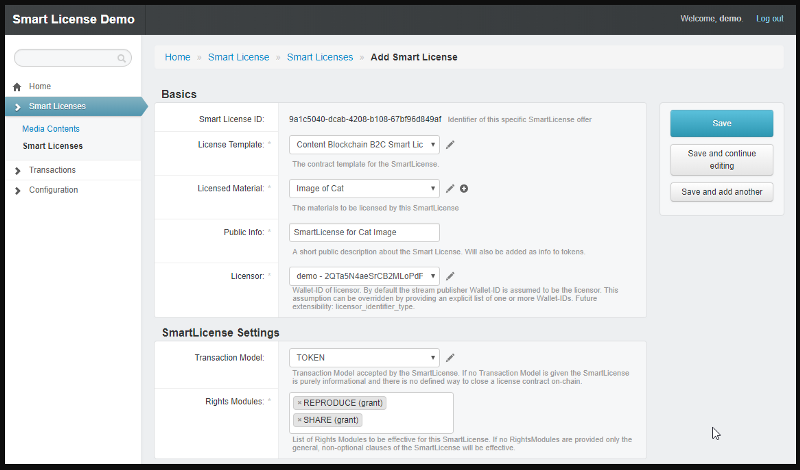
Smart License Template
L’utilisation du générateur de Smart License commence par la sélection d’un template de Smart License qui définit l’étendue de la Smart License, par exemple les droits d’utilisation du contenu licencié.Accompagné de quelques clauses standard, d’obligations et de restrictions optionnelles, la Smart License constitue l’offre d’un contrat de licence.
Pour chaque type de contenu, (texte, image, audio, vidéo), pour tout format de media et tout type de modèle d’affaires, un template peut être généré, par exemple une Smart License pour une transaction B2C pour des images de presse ou un template de Smart License pour une transaction en B2B concernant des livres numériques.
Le texte du template de la Content Blockchain Smart License (créé par The Content Blockchain Project) est dédié au domaine public sous licence CC0. Il est en outre prévu de créer un référentiel de modèles de licences Smart pouvant, selon la licence, être concédé sous licence ou utilisé librement pour tout type de modèle de transaction.
Un template de Smart License se compose des éléments suivants (exemplaires, voir l’avis légal de Smart License)
- L’avertissement et la préface du contrat de licence;
- Les modules de droits;
- L’exclusion de garanties et responsabilités;
- Les conditions générales.
Tous les composants du template de Smart License contiennent des définitions légales sous forme de texte lisible par des humains, tout comme le résultat final du processus de création d’une Smart License sera un contrat de licence lisible par un être humain.Ainsi, les Smart Licenses sont compréhensibles pour tout le monde, y compris les profanes, et non uniquement par des machines ou des juristes.
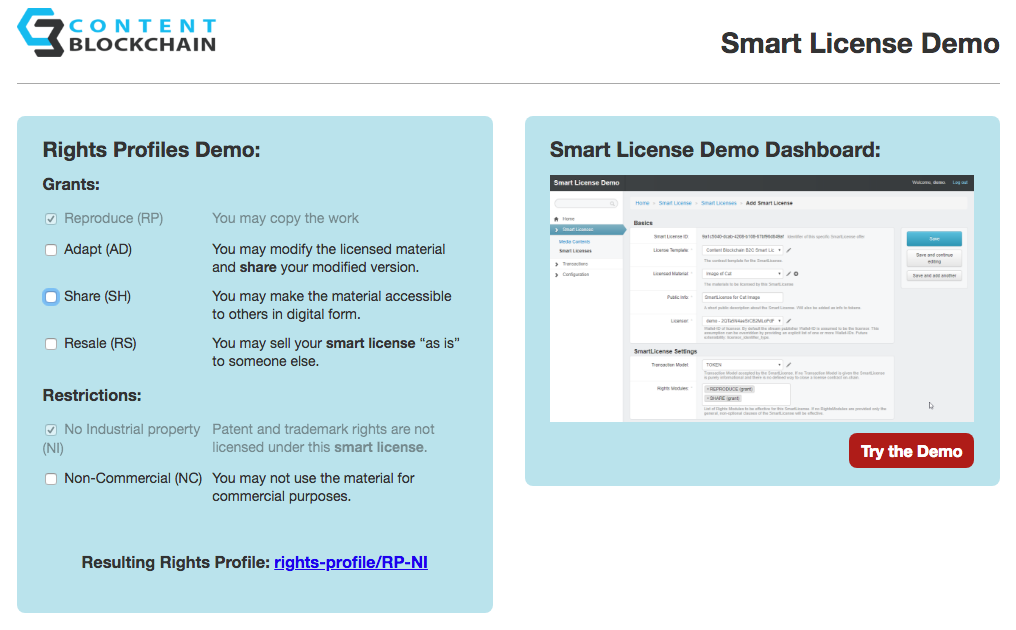
Modules de droits et profil de droits.
Lorsque le choix d’un template adapté à la Smart License pour un business particulier a été fait, les détenteurs de droits et ceux qui accordent la licence peuvent choisir parmi un nombre limité de modules de droits et de conditions de licence qui définissent les usages autorisés pour le contenu digital concerné.
Pour donner un exemple, les modules de droits et les conditions pour un template de Smart License pour des transactions B2C pour du contenu de type articles de presse pourrait être:
- Droits: Adaptation, prêt, reproduction, revente, partage, distribution, location
- Restrictions: non commercial, pas de droits de propriété industrielle
- Obligations: Attribution, juste partage, indiquer les adaptations
La combinaison des droits sélectionnés et des conditions de licence, dépendant du template de la Smart License, va créer un profil de droits pour la Smart License.
A noter, la différence entre les Smart Licenses et les Langages de Description de Droits (Rights Markup Languages): RML essaie de décrire un standard pour exprimer des droits, des règles et des conditions qui conviennent à une large catégorie de transactions de type licence, alors que la Smart License concerne la régulation d’un cas individuel pour une cas d’usage spécifique.Un template de Smart License pourrait aussi bien inclure des éléments de rights markup language comme ODRL ou ONIX-PL ou Rights ou d’autres standards établis.
Smart License
Complété par des règles générales, telles que les clauses de non-responsabilité et les conditions standard du modèle Smart License, de possibles variations dans les conditions de licence ainsi que des éléments supplémentaires comme le prix par licence, le profil de droits constituera le contenu de la Smart License et prendra la forme d’une structure de données JSON.
En particulier, la Smart License se compose des éléments suivants:
- Le code ISCC du contenu auquel la licence s’applique
- Le profil de droits (modules de droits et conditions de licence)
- Le prix par licence
- Les modes d’activation (par exemple le paiement et les autres moyens de conclure un contrat de licence)
- L’identifiant du portefeuille de celui qui dispense la licence
- La définition légale générale et le contrat de licence tels que spécifiés par le template de la Smart License.
Définition Légale
Par définition et d’un point de vue légal, la Smart License est une offre de conclusion d’un contrat de licence, qui contient tous les aspects nécessaires à cet effet.Le licencié peut accepter l’offre en effectuant un acte défini par celui qui dispense la licence, par exemple un paiement sur la Content Blockchain.
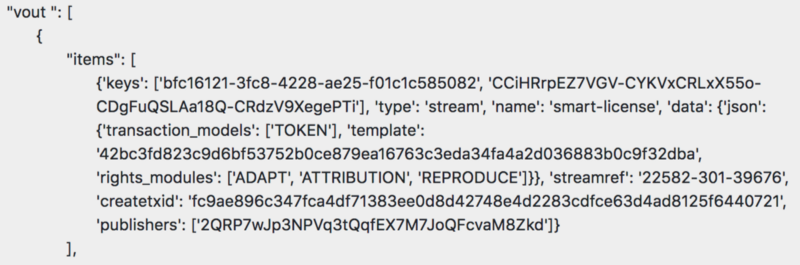
Enregistrer une Smart License sur la Content Blockchain
Le générateur de Smart License va créer un une version texte lisible par des être humains du contrat de licence à partir de tous les composants de la Smart License de même que du fichier de données JSON, qui inclut des valeurs spécifiques (par exemple le contenu légal) de tous les composants d’une manière lisible par une machine.
De plus, un identifiant unique aléatoire, une chaîne UUID4 (par exemple: f846a304158b-44cf-8c1b-f8e3ce8092f4) va être créée. Elle va désigner la Smart License individuelle. Ensemble, la chaîne UUID4 et le fichier JSON permettent de recréer tout contrat de licence individuelle sous la forme d’un texte lisible par un être humain.
https://explorer.coblo.net/tx/44f34b67100fec4ad88601ce037fe81fb480c29b4da0791a38771f1207b29166?raw
Le fait d’enregistre une Smart License dans le flux Smart License de la Content Blockchain, lie de manière inséparable ensemble les éléments suivants:
- Le code ISCC du contenu numérique
- L’UUID4 en tant que clé primaire pour la Smart Licenses
- Le fichier de données JSON pour la Smart License individuelle (incluant de l’information au sujet du template de la Smart License)
- L’identifiant du portefeuille du détenteur des droits (et éditeur de l’item de flux)
- L’Horodatage de l’enregistrement de la transaction
- Les détails de la transaction qui a généré l’item de flux.
Enregistrer une Smart License est une transaction dans la Blockchain. Comme le «flux Smart License» dans la Blockchain est un flux public, n’importe quelle application peut effectuer une recherche sur un ISCC ou une clé UIID4, pour obtenir l’accès aux termes de la licence attachée à une offre spécifique de contenu d’une manière lisible aussi bien par les machines que par les êtres humains.
En reconsidérant le processus depuis le début, c’est à dire avec la création et l’enregistrement d’un identifiant ISCC, la création et l’enregistrement d’une Smart License sur la Content Blockchain, cela signifie que non seulement toute personne ayant accès au contenu sera en mesure de générer le même ISCC à partir du contenu lui-même et d’identifier ce contenu de manière non ambigüe, mais aussi toute personne ayant accès au contenu sera en capacité d’accéder aux termes de la licence attachée à ce contenu, à partir du moment où le détenteur des droits aura enregistré la Smart License de ce contenu sur la Content Blockchain.
Selon le type de contenu et de modèle d’affaires, plus d’une Smart License peuvent être enregistrées pour un seul ISCC, par exemple pour un contenu spécifique. Dans ces scénarios, plusieurs templates distincts de Smart License s’appliqueront, par exemple un ebook pourrait être offert directement aux consommateurs, ou bien à un intermédiaire ou à un revendeur.
Notez bien qu’une Smart License peut constituer une offre de licence publique lorsqu’elle est enregistrée publiquement sur la Content Blockchain. Cependant, tous les cas d’affaires n’incluent pas comme scénario préférentiel le fait que les termes de la licence soient publiquement accessibles sur une blockchain publique.Pour autoriser un scénario avec un accès restreint au contenu de la Smart License, lors des prochaines mises à jour il sera possible de créer une offre de licence ciblée via une Smart License Confidentielle. Avec une Smart License Confidentielle, ce n’est pas le fichier de données JSON intégral qui sera publié sur le flux de la Smart License, mais plutôt un hachage du fichier de données JSON créé au préalable. Cela permettra de garantir l’intégrité de la licence et de l’ancrer sur le grand registre public de la blockchain. Mais l’échange à propos du contenu de la Smart License devra se produire de manière bilatérale.
Identification de l’utilisateur
La gouvernance, les autorisations et l’identification des détenteurs de droits sont les sujets de discussion essentiels concernant les futurs développements du Content Blockchain Project.
Comme les flux de données sur la Content Blockchain sont soit totalement ouverts à la lecture et à l’écriture soit contrôlés via des permissions, les questions suivantes sont parmi celles qui doivent être adressées pour faire partie de la régulation de la gouvernance générale de la Content Blockchain: Qui aura l’autorisation d’ouvrir les flux de données? Quels sont les prérequis pour opérer un fluxet écrire sur un flux dans la Content Blockchain? Comment une blockchain, qui est par principe considérée comme ouverte, pourra-t-elle gérer et gouverner des flux de données?
Notez que le contenu lui-même n’est PAS stocké dans la blockchain, et que l’autorisation d’accès au contenu est gérée par des applications extérieures à la blockchain qui peuvent définir leurs propres règles de confiance. D’autre part, l’acte de publier une Smart License pourrait implicitement être interprété comme une proclamation non vérifiée et illégitime de propriété sur le contenu concerné.
Pour protéger davantage les droits de propriété intellectuelle et afin de prévenir les abus, the Content Blockchain va considérer la possibilité de développer diverses fonctionnalités, notamment :
- Des flux de données contrôlés dans lesquels seuls les participants autorisés peuvent publier des Smart Licenses
- Responsabilité de l’éditeur par auto-certification ou certification par un tiers de confiance indépendant
- Un «flux des abus» géré par la communauté
- Score réputationnel basé sur l’historique de la chaîne.
Une question? Une réaction? Merci de contacter:
https://contentblockchain.org/contact/ou Sebastian Posthou via Telegram.














{kind=link}